- Попытка сканирования сайта JavaScript без рендеринга
- Как сканировать сайты JavaScript с помощью Sitebulb
- Что это за время рендеринга?
- Пример тайм-аута рендеринга
- Рекомендуемое время рендеринга
- Побочные эффекты сканирования с помощью JavaScript
- Как обнаружить JavaScript-сайты
- Брифинг для клиентов
- Попытка ползать
- Ручная проверка
- Дальнейшее чтение
Сканирование веб-сайтов в 2018 году не так просто, как это было несколько лет назад, и это в основном связано с ростом использования сред JavaScript, таких как Angular, React и Meteor.
Традиционно сканер работал бы, извлекая данные из статического HTML-кода, и до недавнего времени большинство веб-сайтов, с которыми вы сталкивались, могли сканироваться таким образом.
Однако, если вы попытаетесь сканировать веб-сайт, созданный с помощью Angular, таким образом, вы не добьетесь большого успеха (в буквальном смысле). Чтобы «увидеть» HTML веб-страницы (а также содержимое и ссылки внутри нее), сканер должен обработать весь код на странице и фактически отобразить содержимое.
Google обрабатывает это в двухэтапном подходе , Первоначально они сканируют и индексируют на основе статического HTML («первая волна» индексации). Затем, когда у них есть ресурсы, доступные для визуализации страницы, они выполняют вторую волну индексации на основе визуализированного HTML.

Попытка сканирования сайта JavaScript без рендеринга
Сначала мы рассмотрим, как будет выглядеть эта первая волна индексации для веб-сайта, созданного в среде JavaScript.
Мой друг ведет сайт, созданный в Backbone, и его сайт предоставляет отличный пример, чтобы увидеть, что происходит.
Рассматривать страница продукта для их самого популярного продукта. С Chrome -> Inspect мы можем увидеть h1 на странице:

Однако, если мы просто просмотрим исходный код на этой странице, h1 не будет видно:

Прокрутка далее вниз по странице источника просмотра покажет вам кучу скриптов и некоторый запасной текст. Вы просто не можете видеть мясо и кости страницы - изображения продуктов, описание, технические характеристики, видео и, самое главное, ссылки на другие страницы.
Таким образом, если вы попытаетесь сканировать этот веб-сайт традиционным способом (используя «HTML Crawler»), все данные, которые обычно извлекает сканер, по существу невидимы для него. И вот что вы получите:
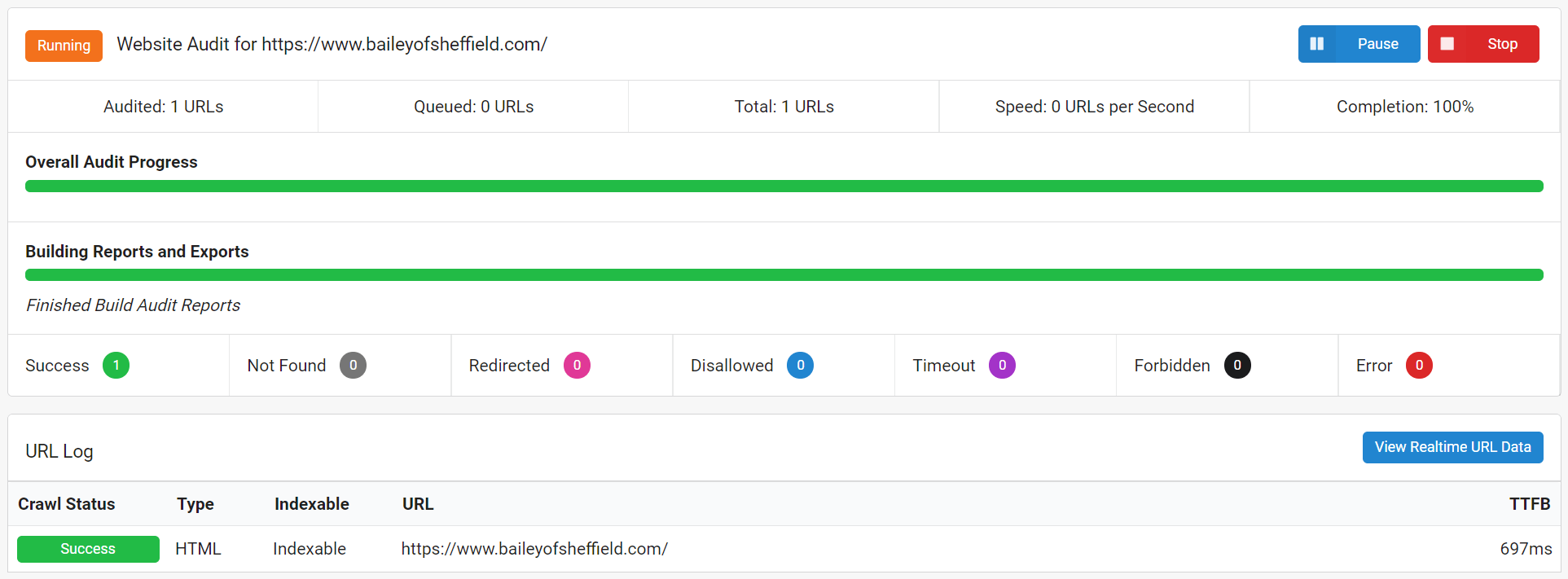
Одна страница.
Если бы Google пришел на свою первую волну индексации, все, что они нашли бы, это одна страница. И одна страница с очень маленьким на этом, в этом.
Поэтому с такими сайтами нужно обращаться по-разному. Вместо того, чтобы просто загружать и анализировать HTML-файл, сканер должен создать страницу так, как это сделал бы браузер для обычного пользователя, позволяя визуализировать весь контент, запуская весь JavaScript для добавления динамического контента.
По сути, сканер должен притвориться браузером, позволить загружать весь контент, и только потом идти и анализировать HTML.
Вот почему вам нужен современный сканер, такой как Sitebulb, установленный в режиме Chrome Crawler, для сканирования таких сайтов.
Как сканировать сайты JavaScript с помощью Sitebulb
Каждый раз, когда вы настраиваете новый проект в Sitebulb, вам нужно выбирать параметры анализа, такие как проверка AMP или расчет оценок скорости страницы.
По умолчанию для сканера используется HTML Crawler, поэтому вам нужно использовать раскрывающийся список, чтобы выбрать Chrome Crawler. В некоторых случаях Sitebulb обнаружит, что сайт использует инфраструктуру JavaScript, и предупредит вас об использовании Chrome Crawler (и предварительно выберет его для вас, как на рисунке ниже).
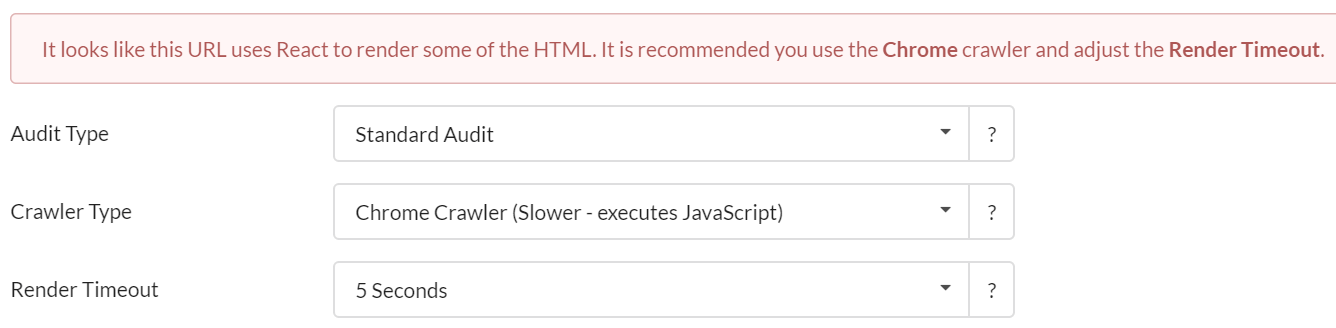
В этих случаях появится новая опция настроек - «Render Timeout».
Большинство людей, вероятно, не будут знать, что относится к тайм-ауту рендеринга или как его установить. Если вы не хотите знать, пропустите раздел ниже и просто оставьте его в рекомендуемых 5 секундах. В противном случае читайте дальше.
Что это за время рендеринга?
Время ожидания рендеринга - это, по сути, то, как долго Sitebulb будет ждать завершения рендеринга, прежде чем делать «снимок HTML» каждой веб-страницы.
Джастин Бриггс опубликовал пост, который является отличным учебником по обработка контента JavaScript для SEO , который поможет нам объяснить, где подходит время рендеринга.
Я настоятельно советую вам пойти и прочитать весь пост, но по крайней мере на снимке экрана ниже показана последовательность событий, которые происходят, когда браузер запрашивает страницу, которая зависит от содержимого, отображаемого JavaScript:

Период 'Render Timeout', используемый Sitebulb, начинается сразу после # 1, Первоначального запроса. Итак, по сути, тайм-аут рендеринга - это время, которое нужно ждать, пока все загрузится и отобразится на странице. Скажем, у вас задано время ожидания рендеринга 4 секунды, это означает, что на каждой странице есть 4 секунды для завершения загрузки всего содержимого и вступления в силу всех последних изменений.
Все, что изменяется через эти 4 секунды, не будет записано и записано Sitebulb.
Пример тайм-аута рендеринга
Я продемонстрирую на примере, наши друзья снова в Бейли из Шеффилда , Если я сканирую сайт без тайм-аута рендеринга, я получаю в общей сложности 30 URL. Если я использую 5 секундный тайм-аут, я получу 51 URL, почти вдвое больше.

(Аудит с 1 URL-адресом для сканирования, если вы помните, был от сканирования с помощью HTML-сканера).
Более подробно об этих двух обходах Chrome было найдено еще 14 внутренних URL-адресов HTML с 5-секундным таймаутом. Это означает, что в аудите без тайм-аута рендеринга контент, содержащий ссылки на эти URL-адреса, не был загружен, когда Sitebulb сделал снимок.
Очевидно, что это может оказать глубокое влияние на ваше понимание веб-сайта и его архитектуры, что можно выделить, сравнив две карты сканирования:

В этом случае было очень важно установить время рендеринга, чтобы Sitebulb мог видеть весь контент.
Рекомендуемое время рендеринга
Понимание того, почему существует тайм-аут рендера, на самом деле не помогает нам решить, на что его устанавливать. Мы просмотрели в Интернете подтверждение от Google о том, как долго они ждут загрузки контента, но мы нигде не нашли его.
Однако мы обнаружили, что большинство людей сходятся во мнении, что 5 секунд обычно считаются «правильными». Пока мы не увидим что-то конкретное от Google или не сможем провести еще несколько собственных тестов, мы будем рекомендовать 5 секунд для времени ожидания рендеринга.
Но все это покажет вам приблизительное значение, которое может видеть Google . Если вы хотите сканировать ВСЕ материалы на своем сайте, вам необходимо лучше понять, как на самом деле отображается содержимое на вашем сайте .
Для этого мы вернемся к консоли Chrome DevTools. Щелкните правой кнопкой мыши страницу и нажмите «Проверить», затем выберите «Сеть» на вкладках в консоли и перезагрузите страницу. Я расположил док справа от моего экрана, чтобы продемонстрировать:

Следите за графиком водопада, который строится, и временем, записанным в сводной панели внизу:

Итак, мы записали 3 раза здесь:
- DOMContentLoaded: 727 мс (= 0,727 с)
- Нагрузка: 2,42 с
- Финиш: 4,24 с
Вы можете найти определения «DOMContentLoaded» и «Load» из изображения выше, которое я взял из поста Джастина Бриггса. Время «Finish» - это именно то время, когда контент полностью отображается и все изменения или асинхронные сценарии завершены.
Если содержание веб-сайта зависит от изменений JavaScript, вам действительно нужно подождать время «Завершить», поэтому используйте это как практическое правило для определения времени ожидания рендеринга.
Имейте в виду, что до сих пор мы смотрели только на одну страницу. Чтобы лучше понять происходящее, вам нужно проверить количество страниц / шаблонов страниц и проверить время для каждого из них.
Если вы собираетесь сканировать с помощью Chrome Crawler, мы настоятельно рекомендуем вам поэкспериментировать с тайм-аутом рендеринга, чтобы вы могли настроить свои проекты так, чтобы каждый раз корректно сканировать весь ваш контент.
Побочные эффекты сканирования с помощью JavaScript
Почти каждый веб-сайт, который вы когда-либо увидите, использует JavaScript в некоторой степени - интерактивные элементы, всплывающие окна, аналитические коды, динамические элементы страницы ... все это контролируется JavaScript.
Однако большинство веб-сайтов не используют JavaScript для динамического изменения большей части контента на данной веб-странице. Для таких веб-сайтов нет никакой реальной выгоды при сканировании с включенным JavaScript. На самом деле, с точки зрения отчетности, буквально нет никакой разницы:

И на самом деле есть несколько недостатков при сканировании Chrome Crawler, например:
- Сканирование с помощью Chrome Crawler означает, что вам нужно извлекать и отображать каждый отдельный ресурс страницы (JavaScript, изображения, CSS и т. Д.), Что требует больше ресурсов как для локального компьютера, на котором работает Sitebulb, так и для сервера, на котором находится веб-сайт. размещен на.
- Как прямой результат # 1 выше, сканирование с помощью Chrome Crawler выполняется медленнее, чем с помощью Crawler HTML, особенно если вы установили длительное время ожидания рендеринга. На некоторых сайтах и с некоторыми настройками может потребоваться больше времени на 6-10 X.
Таким образом, если вам не нужно сканировать с помощью Chrome Crawler, поскольку веб-сайт использует структуру JavaScript или если вы специально хотите посмотреть, как веб-сайт реагирует на сканер JavaScript, имеет смысл сканировать с помощью HTML Crawler по умолчанию.
Как обнаружить JavaScript-сайты
Для краткости я использовал фразу «сайты JavaScript», где я на самом деле имею в виду «сайты, которые зависят от контента, представленного JavaScript».
Скорее всего, тип веб-сайтов, с которыми вы сталкиваетесь, будет использовать одну из самых популярных платформ JavaScript, такую как:
- угловатый
- реагировать
- встраивать
- позвоночник
- Вью
- метеор
Если вы имеете дело с веб-сайтом, на котором работает одна из этих платформ, важно, чтобы вы как можно скорее поняли, что имеете дело с веб-сайтом, который принципиально отличается от веб-сайта, не поддерживающего JavaScript.
Брифинг для клиентов
Очевидно, что первый порт захода, вы можете сэкономить время, делая работу по обнаружению с тщательным инструктажем с клиентом или их командой разработчиков.
Тем не менее, хотя приятно думать, что каждый брифинг для клиентов будет давать вам такую информацию заранее, я знаю из мучительного опыта, что они не всегда открываются с кажущимися очевидными деталями ...
Попытка ползать
Начинать процесс аудита с помощью Chrome Crawler на самом деле не будет стоить вам слишком много времени, поскольку даже на самых «нишевых» веб-сайтах имеется более одного URL.

Хотя это не означает, что вы определенно имеете дело с веб-сайтом JavaScript, это был бы довольно хороший показатель.
Это, безусловно, стоит иметь в виду, если вы типа «запусти и забудь», или вы склонны оставить Sitebulb на ночь с очередью сайтов для аудита… к утру вы будете горько разочарован.
Ручная проверка
Вы также можете использовать инструменты Google, чтобы помочь вам понять, как веб-сайт создан. Используя Google Chrome, щелкните правой кнопкой мыши в любом месте веб-страницы и выберите «Проверить», чтобы открыть Консоль Chrome DevTools ,
Затем нажмите F1, чтобы открыть настройки. Прокрутите вниз, чтобы найти отладчик, и отметьте «Отключить JavaScript».
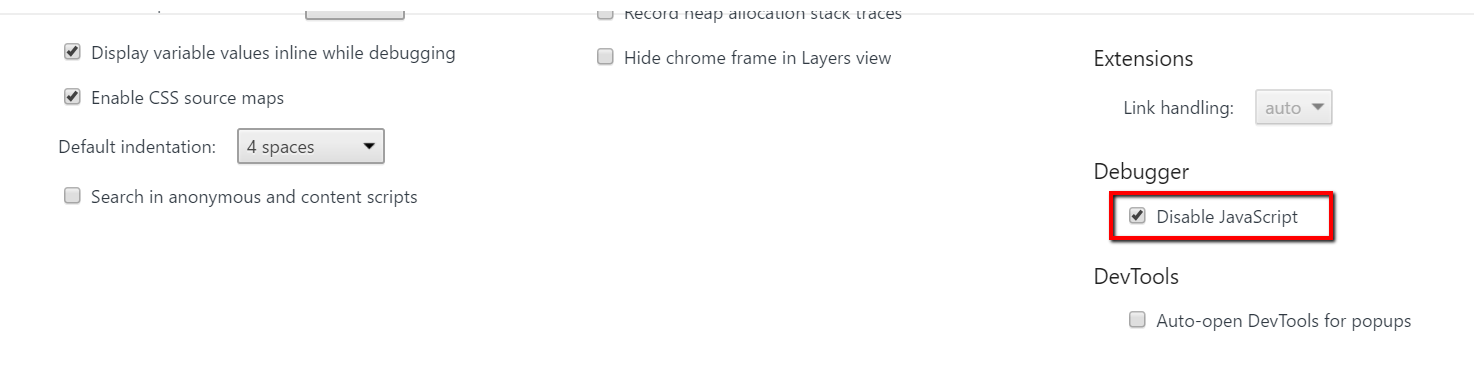
Затем оставьте консоль DevTools открытой и обновите страницу. Содержимое остается неизменным или все исчезает?
Вот что происходит в моем примере с Бэйли из Шеффилда:

Заметили что-нибудь пропавшее?
Хотя это довольно очевидный пример того, как веб-сайт не работает с отключенным JavaScript, также следует иметь в виду, что некоторые веб-сайты загружают только часть контента с помощью JavaScript (например, галерею изображений), поэтому часто стоит проверить количество шаблонов страниц, как это.
Дальнейшее чтение
JavaScript SEO все еще относительно новый и недокументированный, однако мы собрали список всех лучшие ресурсы для изучения JavaScript SEO В том числе руководства, эксперименты и видео. Мы будем держать ресурс в курсе новых публикаций и разработок.
Похожие
Как научиться SEOНаличие веб-сайта, полностью использующего лучшие практики SEO, является неотъемлемой частью обеспечения его оптимальной эффективности. Знание того, как изучать SEO и его основы, может быть полезно для получения лучшего контроля над вашим сайтом и его способности привлекать интернет-трафик. Что такое SEO?
... помощью групповые календари , Групповые календари централизуют работу отдела маркетинга, предоставляя удобный для всех доступ к календарю. Это позволяет заранее составить график ключевых слов и целей SEO, чтобы обеспечить своевременную реализацию ваших маркетинговых целей. Еще одним инструментом, предоставляемым Workzone, который подходит для SEO, являются оповещения по электронной почте. Что такое SEO и как оно работает
... словиях растущей конкуренции и цифрового мира методы поисковой оптимизации могут иметь все значение для вашего бизнеса. Исследования показывают, что компании на первой или второй странице поисковых систем имеют значительно большее количество клиентов, чем компании на других страницах. Таким образом, чем ближе к номеру, тем больше успех компании. Как вы определяете SEO?
... как SEO или поисковая оптимизация. Эта статья поможет вам определить SEO и как работает поисковая система. SEO - это метод оптимизации рейтинга веб-страницы или домена. Итак, как это работает. Хотя мы обсудим это позже подробно, но для краткости, ваш сайт или веб-страница имеют определенное содержание. В этом контенте есть определенные ключевые слова, которые помогают поисковым системам узнать, что такое контент, а затем сравнивают его с введенной вами информацией. Если это будет Как использовать эффективные метатеги
Если вы хотите веб-сайт, который привлекает множество посетителей из результатов поиска, не забывайте о значении метатегов. Мета-теги не просматриваются непосредственно на веб-сайте, но читаются, классифицируются и используются поисковыми системами для интерпретации содержимого вашей страницы. Хорошие метатеги помогают «оптимизировать» ваш сайт, когда вы используете правильные ключевые слова в тексте метатега. Хотя метатеги сами по себе не могут гарантировать полную оптимизацию веб-сайта, PR это новый SEO
Десять лет назад, даже 5 лет назад, SEO было легко. Выйдите, разместите связку ссылок в некоторых комментариях блога или отправьте несколько массовых писем веб-мастерам, рекламирующим ваш сайт, вставьте ссылки и подождите, пока Google не вознаградит вас за высокий уровень поиска. Вам даже не нужно было иметь понятный контент на вашем сайте, вам просто нужно было много ссылок любого качества на ваш сайт, и вы бы выиграли. Эти времена давно прошли. Сегодня использование тактики, существовавшей Sitemaps: ответы на ваши главные вопросы
... помощью традиционного органического поиска. 3. Важны ли еще карты сайта? Если вы хотите, чтобы поисковые системы могли найти все страницы на вашем сайте, вам определенно понадобится карта сайта XML. Если вы планируете новый веб-сайт или обновляете свой текущий веб-сайт, карты сайта являются отличным стратегическим инструментом для планирования структуры URL, информационной иерархии и контента. HTML-карты сайта не являются необходимостью, если вы создали сайт, на котором Стоп-слова - как работают стоп-слова?
... слова - это слова, которые могут считаться не относящимися к набору результатов, отображаемых при поиске в поисковой системе. Примеры:, и, из, для, с, без, был. Конечно, не имеет значения , зависит от выполненного поиска, потому что контекст поиска будет иметь все значение для каждого слова, используемого в исследовании. Но почему я поднимаю эту проблему? Потому что многие люди, которые стремятся что-то сделать SEO 7 тревожных ошибок SEO (включая решения), которые мы часто рассматриваем в интернет-магазине
... как с, так и без www, что ваш магазин не подходит для мобильных устройств, и что вы не используете заголовки h1 и h2 должным образом. Конечно, для такого рода основной ошибки SEO у вас есть контроль над 2017 года. В этой статье вам будет рассказано, в чем заключается проблема, насколько она важна, и одно (или более) решение для устранения ошибки. Вот 7 тревожных ошибок SEO: # 1. У вас плохое или дефектное описание продукта В чем Видео SEO и YouTube: стоп! Ты делаешь это неправильно
Только видео YouTube отображаются в Google, верно? Одно из самых распространенных заблуждений в мире видео SEO заключается в том, что если вы хотите, чтобы ваше видео показывалось в Google, вам необходимо загрузить его на YouTube. Это просто не тот случай. И этот результат от наших друзей в MoneyWeek доказывает это. Как обеспечить подлинную стратегию SEO
SEO - это стратегическая форма искусства, и она постоянно меняется и развивается, и, что, пожалуй, наиболее важно, это та область, в которой вы должны найти баланс между сосредоточением внимания на поисковой привлекательности вашего контента и обеспечением того, чтобы вы всегда обеспечивали подлинность своего контента. , По словам Хабспота, 61% маркетологов считают, что улучшение SEO и расширение их органического присутствия является их главным приоритетом для входящего маркетинга, и в
Комментарии
Но что, если это ключевое слово не дает продажи на вашем сайте, в то время как «натуральная еда для собак» делает?Но что, если это ключевое слово не дает продажи на вашем сайте, в то время как «натуральная еда для собак» делает? Это понятно: вы должны сосредоточить свою SEO-стратегию на этом термине и на всех тех, которые показывают лучший коэффициент конверсии. Дополнительным преимуществом Adwords является то, что, используя тип широкого соответствия, ваши пользователи могут раскрывать термины, о которых вы не подозревали, а также ваши конкуренты не Несмотря на эту инструкцию, путешественника сначала обескуражили, потому что он уже выучил все это у жителей деревни - как это поможет ему сейчас?
Несмотря на эту инструкцию, путешественника сначала обескуражили, потому что он уже выучил все это у жителей деревни - как это поможет ему сейчас? Когда путешественник жаловался, Уогли просто отвечал: «Терпение, терпение». После длительного периода постоянных усилий, путешественник начал замечать, что рейтинг его веб-сайта начинает расти - учения Уогли сработали! Он обрел уверенность и продолжал выполнять эти простые, логичные упражнения на своем сайте каждый день. Вскоре несколько Вы представляете, что SEOBook (в основном) - это то же самое, что через пять-десять лет, как сейчас?
Вы представляете, что SEOBook (в основном) - это то же самое, что через пять-десять лет, как сейчас? В мое (короткое) время, как SEO, кажется, что единственное реальное заметное изменение - это один редизайн. Какие рыночные условия вы ожидаете, чтобы частично повлиять на ваш бизнес? Или вы будете в значительной степени игнорировать их и сдвигаться по мере их появления? Не обращая внимания на какую-либо конкретную компанию, Теперь я знаю, что вы думаете: «PPC противоположен органическому SEO, так как же это метод вне страницы»?
Теперь я знаю, что вы думаете: «PPC противоположен органическому SEO, так как же это метод вне страницы»? Ну, вот почему я сохранил его до последнего, потому что, конечно, это не тот, который вы бы использовали сразу, это скорее план B , план резервного копирования на случай, если ничего не получится. КПП это все еще метод вне страницы, который значительно увеличит ваш трафик. Подумайте об этом, через несколько Что делают ваши конкуренты, и, что более важно, что они делают правильно?
Что делают ваши конкуренты, и, что более важно, что они делают правильно? Книга IV: SEO веб-дизайн Часть SEO разрабатывает вашу страницу должным образом. В этой книге мы научим вас, как лучше всего создать (или настроить) свою страницу для максимальной эффективности SEO. Книга V: Создание контента Одной из самых важных вещей, которые вам нужно сделать для своего веб-сайта, является создание контента. Часть SEO - это привлечение Мы все слышали этот термин (также называемый его аббревиатурой SEO), но что, черт возьми, это значит и как он применяется к вашему интернет-магазину?
Мы все слышали этот термин (также называемый его аббревиатурой SEO), но что, черт возьми, это значит и как он применяется к вашему интернет-магазину? Что такое SEO? SEO заключается в том, чтобы люди могли найти ваш магазин в результатах поиска. Независимо от того, ищет ли кто-то ваш бренд по названию или ищет в магазине то, что вы продаете, вы можете сделать несколько простых вещей (и что Storenvy уже делает для вас!), Чтобы поисковые системы знали о вашем WilmerHale: Если бы вы могли сделать что-нибудь этим летом как стажер SEO, что бы это было?
WilmerHale: Если бы вы могли сделать что-нибудь этим летом как стажер SEO, что бы это было? Кастильо: я смог наблюдать за имитацией судебного разбирательства, и было восхитительно видеть, как четко обе стороны подошли к делу; все было очень целеустремленно. Участие в пробном испытании было бы прекрасной возможностью как продемонстрировать, так и развить навыки для испытания. WilmerHale: Расскажите нам о себе забавный факт. SEO это поисковая оптимизация, как это может быть плохо?
SEO это поисковая оптимизация, как это может быть плохо? Миф рождается из плохих практик, чтобы влиять на позиционирование . Не все страницы реализуют эти действия SEO (известные как Black Hat SEO ), хотя мы должны признать, что некоторые из них эффективны. SEO так же плох, как инструменты и методы, которые вы используете; Если вы честны, то вам нечего бояться. На самом деле, если вы используете такие методы, как фермы ссылок, но делаете это очень хорошо, шансы Что, если вы хотите проверить, что это хорошая идея, чтобы поместить ключевое слово в тег заголовка?
Что, если вы хотите проверить, что это хорошая идея, чтобы поместить ключевое слово в тег заголовка? Как бы вы пошли об этом? Я собираюсь объяснить, как, но позвольте мне начать с этого предисловия: это для проверки теории SEO . Это не та вещь, которую вы хотите делать на своих основных сайтах, потому что она медленная . Не волнуйся; мы вернемся к методам «реального мира» позже в этом посте. А пока, просто поймите, что это все о выявлении индивидуальных Так что же это за модные ОС, такие как Ubuntu, Mint, Fedora, openSUSE и другие довольно графические ОС, которые люди называют разновидностями Linux?
Так что же это за модные ОС, такие как Ubuntu, Mint, Fedora, openSUSE и другие довольно графические ОС, которые люди называют разновидностями Linux? Ну, это Linux плюс менеджеры окон (обычно X Window) и среды рабочего стола, работающие поверх него, чтобы они выглядели и вели себя как оконная операционная система Mac или Windows. X Window предоставляет базовые сервисы управления окнами, а рабочий стол (обычно GNOME и KDE) предоставляет все причудливые украшения, которые делают его удобной альтернативой Но это совсем другая история, когда вы спрашиваете нас о том, «что мы сделали, чтобы сделать наших клиентов счастливыми?
Но это совсем другая история, когда вы спрашиваете нас о том, «что мы сделали, чтобы сделать наших клиентов счастливыми?» Хороший и квалифицированный специалист по SEO может представить вам портфолио и примеры работ. Он может предоставить вам проверенный послужной список, который он заработал за эти годы. Хотя вы не можете ожидать идеальной десятки во всех его работах, он должен быть в состоянии представить вам приличное количество успешных работ и счастливых клиентов,
Что это за время рендеринга?
Содержимое остается неизменным или все исчезает?
Что такое SEO?
Как вы определяете SEO?
3. Важны ли еще карты сайта?
Но почему я поднимаю эту проблему?
Но что, если это ключевое слово не дает продажи на вашем сайте, в то время как «натуральная еда для собак» делает?
Несмотря на эту инструкцию, путешественника сначала обескуражили, потому что он уже выучил все это у жителей деревни - как это поможет ему сейчас?
Вы представляете, что SEOBook (в основном) - это то же самое, что через пять-десять лет, как сейчас?
Какие рыночные условия вы ожидаете, чтобы частично повлиять на ваш бизнес?

