Во-первых, определение:
Стоп-слова - это слова, которые могут считаться не относящимися к набору результатов, отображаемых при поиске в поисковой системе. Примеры:, и, из, для, с, без, был.
Конечно, не имеет значения , зависит от выполненного поиска, потому что контекст поиска будет иметь все значение для каждого слова, используемого в исследовании.
Но почему я поднимаю эту проблему? Потому что многие люди, которые стремятся что-то сделать SEO в итоге они задаются вопросом о целесообразности правильного использования стоп-слов в своем контенте: заголовках, мета-описании, мета-ключевых словах и в контенте.
Прежде чем продолжить, важно понять, как поисковые системы работают со словами фразы: по заданной фразе поисковая система разбивает токены, причем каждый токен является подмножеством, образованным словами этой фразы. Наталия описала, как этот процесс работает, в статье в Главном агентстве как поисковые системы обрабатывают якорный текст , Пример был:
Предположим, что поисковая система находит ссылку с якорным текстом «Десять быстрых советов». Преобразование в токены:
- "Десять быстрых советов"
- «Десять»
- «Советы»
- «Быстрый»
- "Быстрые советы"
- "Десять советов"
- "Десять постов"
Поняв, как фразы обрабатываются в поиске, мы переходим к обработке стоп-слов и как поисковые системы идентифицируют возможные стоп-слова.
Стоп-слова - как Google определяет?
Я нашел "старый" пост ( август 08 ) на сайте SEObytheSEA, сообщающем патент Google о том, как ваша поисковая система может работать для определения стоп-слов в соответствии с поиском, и работает следующим образом:
- Для данного поиска он разбивается на токены, и наборы результатов собираются для токенов, содержащих возможные стоп-слова и без возможного стоп-слова; результаты, полученные в наборах, сравниваются, определяется их сходство и определяются возможные стоп-слова:
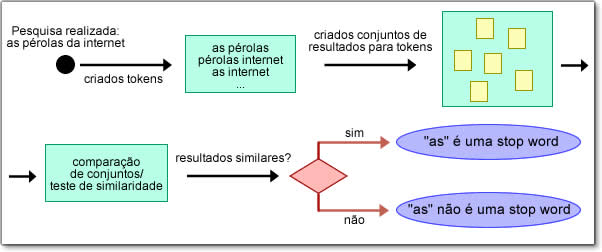
Сложно? Давайте посмотрим пример: при выполнении поиска " другие «В Google набор первых 10 результатов состоит из:
- 4, среди первых 7 результатов, по фильму "Другие"
- 3 музыкальных результата
- 3 Литературные результаты
С другой стороны, поиск " другой ", Возвращает в своем наборе первые 10 результатов:
- 2 результатов для музыки
- 2 видео результаты (например, Фабио де Мело и Кид Абельха)
- Google Maps
- 1 на фильм
- еще 5 результатов
То есть определенная статья «os» в данном случае полностью соответствует набору представленных результатов. С другой стороны, сравнивая набор результатов поиска «жемчужины Интернета» (1) с набором «жемчужин Интернета» (2), можно заметить, что 7 из первых 10 результатов в (1) входят в число 10 первое в (2) - сходство 70%. Определенная статья «как» может рассматриваться как стоп-слово.
заключение
Фактически, патент Google имеет смысл и может фактически использоваться, или, возможно, очень близкая версия этого патента, выданная Google в прошлом году. Чтобы узнать, может ли термин считаться стоп-словом, действительно необходимо пройти тест и оценить результат.
Но имейте в виду, что правильное использование стоп-слов также влияет на решение пользователя о клике. Плохо написанные предложения могут увеличить неприятие пользователей, как я прокомментировал в своей статье оптимизация слов с ошибками ,
В примерах, приведенных в этой статье, я протестировал только первые 10 результатов по 2 токенам, Google может тестировать намного больше и установить степень сходства (70%, 30%, 90%), как это кажется более подходящим, но тесты в порядке убедительны. Что вы думаете? Какой у вас опыт со стоп-словами? Оставьте свое сообщение в комментариях, до следующего!
Похожие
Как научиться SEOНаличие веб-сайта, полностью использующего лучшие практики SEO, является неотъемлемой частью обеспечения его оптимальной эффективности. Знание того, как изучать SEO и его основы, может быть полезно для получения лучшего контроля над вашим сайтом и его способности привлекать интернет-трафик. Как обновление основного алгоритма Google повлияло на SEO?
Еще в марте этого года Google подтвердил, что они «выпустили обновление основного алгоритма» в серьезном твите в своем аккаунте Google SearchLiasion в Twitter: Как использовать эффективные метатеги
Если вы хотите веб-сайт, который привлекает множество посетителей из результатов поиска, не забывайте о значении метатегов. Мета-теги не просматриваются непосредственно на веб-сайте, но читаются, классифицируются и используются поисковыми системами для интерпретации содержимого вашей страницы. Хорошие метатеги помогают «оптимизировать» ваш сайт, когда вы используете правильные ключевые слова в тексте метатега. Хотя метатеги сами по себе не могут гарантировать полную оптимизацию веб-сайта, Как вы определяете SEO?
Сертификационный курс по входящему маркетингу глава-9 С этой статьей мы собираемся начать новую часть нашего курса сертификации входящего маркетинга. Мы будем говорить об оптимизации ваших сайтов для поисковых систем. Когда вы ищете что-то, скорее всего, вы посещаете поисковую систему и вводите информацию. Затем эта поисковая система перенаправляет вас на страницу, на которой есть множество сайтов, соответствующих вашей 5 кампаний Google AdWords для продвижения вашего бизнеса
... как в большинстве других типов кампаний. Вы добавляете несколько строк текста, ставку, бюджет, языки, местоположения и количество элементов, а остальное оптимизируется, чтобы найти пользователей для вас. Google AdWords автоматически создает разные объявления в разных форматах и для разных сетей, тестирует разные комбинации и чаще показывает автоматически наиболее эффективные объявления. AdWords также автоматизирует таргетинг и назначение ставок, поэтому вы получаете Новый SEO-аудит в Google Lighthouse - краткий обзор
Немного покопавшись в отчете о производительности Google Lighthouse, я был взволнован новым аудитом SEO, который вот-вот должен был упасть. Я надеялся, что это даст некоторые новые интересные идеи и, возможно, будет несколько новых факторов, которые меня заинтересуют. Аудит теперь доступен в Chrome Canary ( Chrome 65 ). К сожалению, посмотрев на это, я разочарован. Он не охватывает намного больше, чем основные Что такое SEO и как оно работает
... работают поисковые системы? Мы сосредоточены на том, как Google выбирает, чтобы объяснить простым способом, что делает работу поисковых систем возможной. Google является наиболее используемым движком как в Португалии, так и в остальном мире, а также в других движках, таких как Yahoo! и Bing основаны на одних и тех же предположениях. Сканирование и индексирование У поисковых систем есть своего рода робот, который постоянно выполняет поиск в 5 инструментов SEO от Google для улучшения вашего SEO
... определяет консоль поиска как бесплатную услугу, которая помогает вам отслеживать и поддерживать присутствие вашего сайта в результатах поиска Google. Это позволяет решить практически любую проблему SEO, перейдя от структурированных данных к спаму. Это важный инструмент, который должен иметь каждый владелец сайта, но его часто упускают из виду. И это позор , потому что, если Google Search Console используется правильно, она может дать очень хорошие результаты Как обеспечить подлинную стратегию SEO
SEO - это стратегическая форма искусства, и она постоянно меняется и развивается, и, что, пожалуй, наиболее важно, это та область, в которой вы должны найти баланс между сосредоточением внимания на поисковой привлекательности вашего контента и обеспечением того, чтобы вы всегда обеспечивали подлинность своего контента. , По словам Хабспота, 61% маркетологов считают, что улучшение SEO и расширение их органического присутствия является их главным приоритетом для входящего маркетинга, и в Каковы лучшие плагины WordPress для Google Analytics?
... как вы узнали, что это работает ? За исключением немедленного захвата потенциальных клиентов, продаж или звонков на приемы, вы не получите ответ на этот вопрос без посторонней помощи. Итак, как вы узнаете, что вся ваша тяжелая работа и энергия действительно привлекают посетителей на ваш сайт? Краткий ответ, Google Analytics . Гугл Аналитика по сути, это сервис Как протестировать локальный сайт с помощью инструментов Google SEO
Недавно мне пришлось сопровождать клиента по внедрению разметки структурированных данных (Schema.org) на большом веб-сайте во время разработки его новой версии. После SEO-аудита я начал этап внедрения с технической командой Agile. Одним из основных ограничений процесса разработки было: мы не должны делать сайт публичным! А с другой стороны, мне потребовалось использовать SDTT ( Инструмент тестирования структурированных
Комментарии
Так как же вы - как маркетолог, который может не иметь полное понимание того, как работает индекс Google Найти и исправить проблемы с индексацией?Наши приглашенные писатели Просмотреть полный профиль участника İlyas , SEO директор в офисе iProspect в Чикаго; Бехлюл Гоктепе , Naspers SEO менеджер и Yiğit потоки в Турции, выступает в качестве генерального директора является основателем SEOZEO kuruu. В прошлом июне (2015) и Google, и Apple; Используя различные технологии для индексирования контента Чтобы постоянно наращивать трафик быстрыми темпами, вам нужно использовать термины для новичков, такие как «Как проиндексироваться в Google?
Чтобы постоянно наращивать трафик быстрыми темпами, вам нужно использовать термины для новичков, такие как «Как проиндексироваться в Google? ». Но трафик из этих типов терминов не будет превращать посетителей в клиентов. Эти ключевые слова составляют более 81% поискового трафика Нила Пателя, но он все еще ищет их, потому что он верит в брендинг и «длинную игру» (правило 7, которое я собираюсь выполнить обратитесь позже в этой статье). У Нила есть несколько предприятий, Так как они работают?
Так как они работают? Длинные ключевые слова более специфичны и актуальны для вашего бизнеса, если они выбраны правильно. Они очень похожи на обычные ключевые слова, но они больше похожи на «ключевые фразы». Если вернуться к более раннему примеру страхования автомобилей, возможно, ваш бизнес продает только страховые автомобили премиум-класса в Торонто. Вот и все - «страхование дорогих автомобилей Торонто» - это ваше первое ключевое слово с длинным Заметьте, что полоса также не совсем зеленая, так как она была полностью «заполнена» с Google?
Заметьте, что полоса также не совсем зеленая, так как она была полностью «заполнена» с Google? Вместо этого, подобно термометру, он заполнен лишь частично на 7/10 пути, чтобы визуально представить оценку PageRank страницы. Вот еще одна страница: Ой! Нуль! Это ужасная страница! Вообще-то, нет. В этом случае я попытался перейти на страницу, которая не существует Как вы можете оставаться в курсе событий в нашей отрасли, когда книги, учебные материалы и даже сообщения в блогах на первой странице Google так быстро устаревают?
Как вы можете оставаться в курсе событий в нашей отрасли, когда книги, учебные материалы и даже сообщения в блогах на первой странице Google так быстро устаревают? Посмотрите на экспертов , Влиятельные лица всегда будут говорить о том, что происходит в контент-маркетинге, в социальных сетях, в конференц-связи и на своих собственных платформах. Кроме того, вы можете просто наблюдать за тем, что Как работают поисковые системы?
Как работают поисковые системы? Прежде чем мы поговорим о том, как оптимизировать данный сайт для поисковых систем, рассмотрим основы работы поисковых систем. Поисковые системы используют математические алгоритмы для сравнения и ранжирования веб-страниц с похожими ключевыми словами и содержанием. Алгоритмы очень сложны, полагаясь на использование веб-роботов, которые постоянно сканируют Интернет, чтобы «кэшировать» (сохранять) каждую веб-страницу, которую они посещают. Не идя дальше, Google обнаружил, что поиски "Рядом со мной" удвоились , Знаете ли вы о прекрасной возможности, которую это представляет, чтобы появиться в первых местах поиска Google?
Заметьте, что полоса также не совсем зеленая, так как она была полностью «заполнена» с Google? Вместо этого, подобно термометру, он заполнен лишь частично на 7/10 пути, чтобы визуально представить оценку PageRank страницы. Вот еще одна страница: Ой! Нуль! Это ужасная страница! Вообще-то, нет. В этом случае я попытался перейти на страницу, которая не существует Как я могу сказать, что Google проиндексировал?
Как я могу сказать, что Google проиндексировал? Консоль поиска Google показывает проиндексированные страницы Несмотря на то, что вам НЕОБХОДИМО сканировать ваш сайт, вы ХОТИТЕ его проиндексировать. Есть несколько способов определить, что Google проиндексировал на вашем сайте. Один из них - просто зайти на Google.com и нажать «Настройки» в правом нижнем 6. Что такое Google Penguin и Google Panda?
6. Что такое Google Penguin и Google Panda? Google Penguin и Google Panda - это два алгоритма, которые служат «фильтрами», установленными Google для наказания сайтов низкого качества и, следовательно, для продвижения других вперед. Google Penguin (Пингвин) проверяет качество ссылок. Если у вас есть обратные ссылки (внешние ссылки на ваш сайт) низкого качества (поступающие с сайтов низкого качества, слишком оптимизированные, неестественные и т. Д.), Вы будете оштрафованы Google Penguin. Знаете ли вы, что делают ваши SEO-конкуренты, как они ранжируются в Google, и сколько трафика они получают?
Знаете ли вы, что делают ваши SEO-конкуренты, как они ранжируются в Google, и сколько трафика они получают? Знание этой информации может быть разницей между будущим успехом или провалом SEO. Вот почему конкурентный анализ является важным шагом при разработке вашей стратегии SEO. В этой главе рассматриваются некоторые инструменты конкурентного анализа SEO, которые могут помочь вам ответить на все (или большинство) ваших вопросов и предоставить вам наиболее точные данные Как я могу получить свой сайт в результатах поиска Google?
Как я могу получить свой сайт в результатах поиска Google? Как я могу опередить своих конкурентов? Если это так, то SEO услуги Цинциннати - это именно то, что может понадобиться вашему сайту. Поисковая оптимизация может привести к увеличению присутствия в сети для вашей компании, что увеличит ваши: Трафик сайта Компания ведет Интернет-продажи Бесплатная онлайн реклама SEO- сервисы Atomic
Стоп-слова - как Google определяет?
Но почему я поднимаю эту проблему?
Стоп-слова - как Google определяет?
Что вы думаете?
Какой у вас опыт со стоп-словами?
Как обновление основного алгоритма Google повлияло на SEO?
Аботают поисковые системы?
Как вы узнали, что это работает ?
Итак, как вы узнаете, что вся ваша тяжелая работа и энергия действительно привлекают посетителей на ваш сайт?
Чтобы постоянно наращивать трафик быстрыми темпами, вам нужно использовать термины для новичков, такие как «Как проиндексироваться в Google?

